
Spiegare per filo e per segno il funzionamento di un sistema acustico complesso e originale come le NPS-1000 è per me compito arduo e sicuramente Renato Giussani ha già dato più di una spiegazione autorevole… Per questo preferisco rimandandare ai seguenti link per una descrizione dettagliata data da parte dell’autore:
Stereofonia e percezione
DSR & NPS – orizzontale
DSR & NPS – verticale
Emissione NPS©
Presentazione NPS-1000
NPS-1000 Insignis
Quello che invece posso fare io è aggiungere qualche pensiero personale in proposito, così come credo di aver capito da un primo studio sul fenomeno e su i vari ascolti del sistema in questione come anche di sistemi in qualche modo imparentati. Non ultimi, tutti gli ascolti di musica fatti dal vivo (alcuni dei quali vedevano il sottoscritto coinvolto come artefice primo dell’evento…)
Alcuni piccoli appunti, dunque, per un piccolo studio sull’NPS, l’originale sistema pensato e realizzato da Renato Giussani con una serie di diffusori dei quali le NPS-1000 rappresentano la massima espressione.
1. Breve premessa
Prima di tutto penso sia giusto ricordare che, analogamente a ciò che accade con le onde elettromagnetiche, le onde acustiche (che altro non sono che delle variazioni della pressione acustica) vengono più o meno “impattate” dai corpi che incontrano durante il loro percorso in maniera diversa a seconda della loro lunghezza d’onda e delle dimensioni dell’ostacolo con cui hanno a che fare.
Quindi più è bassa la frequenza della sorgente, e dunque più è lunga la sua lunghezza d’onda, più deve essere grande l’ostacolo che deve avere di fronte per poter essere in qualche modo modificata/deviata. In modo analogo, tanto più alta è la frequenza, tanto deve essere piccolo l’ostacolo affinchè esso non modifichi/devii la stessa.
Perchè ricordo cose che a molti di voi forse sembreranno banali? E’ presto detto: noi ci illudiamo che una riproduzione stereofonica possa ricostruire una scena sonora così come la potremmo avere in condizioni di ascolto dal vivo. Ho usato appositamente il termine illudiamo perchè – come vedremo – sarà il nostro cervello che andrà un po’ imbrogliato affinchè si possa simulare una situazione vicina alla realtà.
Quando ascoltiamo “dal vivo” la musica, le informazioni che arrivano alle nostre orecchie sono una sommatoria di suono diretto più tutte le sue riflessioni. Come si creano le sensazioni di direzionalità e profondità? Due sono le tecniche che il nostro sistema uditivo (compreso cervello) utilizza:
- il fatto che i nostri padiglioni auricolari siano posti a diversi centimetri di distanza l’uno dall’altro fa si che una sorgente sonora arrivi a ciascun orecchio con una intensità e un tempo proporzionale e diverso alla sua distanza;
- il fatto che i nostri padiglioni auricolari abbiano una forma così particolare e orientati in modo tale da creare una specie di schermo che divide la nostra testa in una zona anteriore e una posteriore. Tutte le pieghe del nostro padiglione creano una serie continua e diversa di difrattori che lavorando a frequenze diverse, diffrangono e/o filtrano diversamente i suoni e contribuiscono a “crearne” il timbro e quindi la profondità nonchè migliora la percezione direzionale.
Quel “quindi” è volutamente messo proprio per attrarre l’attenzione sul fatto che spesso si sottovaluta il parametro timbro per la localizzazione/ricostruzione spaziale del suono.
Noi spesso non ci pensiamo, ma dal momento in cui nasciamo, non facciamo altro che imparare ad ascoltare, ricordare, comparare e riprodurre segni, suoni e idee. Così facendo, noi impariamo ad ascoltare i suoni che ci circondano e, tramite continui confronti con i riferimenti di quello che già conosciamo, impariamo a distinguere sia il tipo di suono, sia la sua distanza da noi. Perchè?
Un fenomeno interessante e utilissimo per noi è rappresentato dal continuo “deteriorarsi” dello spettro sonoro che rappresenta il timbro di una sorgente sonora all’aumentare della sua distanza dall’ascoltatore. Il fatto che le sue armoniche superiori vadano sempre più ad affievolirsi confondendosi con il “timbro” dell’ambiente (leggi anche suono riverberato), fa sì che noi si possa ancora – entro certi limiti – riconoscerne l’identità, mentre il nostro cervello interpreterà questo “appannamento” progressivo del timbro come a un allontanamento della sorgente sonora da noi.
Andiamo avanti cercando di capire come il mondo dei suoni ineragisce con noi (incluso il nostro cervello…)
Sappiamo che siamo sensibili al vettore intensità acustica (modulo e direzione; cfr.: dsr nps orizzontale); questo è uno dei mezzi con cui il nostro cervello interpreta la localizzazione del suono. Il diverso ritardo con cui esso arriva alle nostre orecchie è un secondo mezzo. La variazione del timbro e il modo in cui il sistema integrato testa-padiglione discrimina lo spettro sonoro frontalmente e posteriormente è un quarto.
Tutti e quattro questi mezzi contribuiscono a fornire le informazioni necessarie al cervello per ricostruire l’immagine sonora. Ma sono utilizzati tutti allo stesso modo indipendentemente dalla frequenza? La risposta è no.
Infatti per come è fatto il nostro sistema uditivo (inclusa la testa e spalle, non dimentichiamo) più il cervello, si scopre che al variare della frequenza, siano utilizzati con successo dal cervello più certi espedienti tra quelli elencati che altri.
Cercando di avvicinarci più a quello che vogliono significare le teorie (e le pratiche) DSR e NPS, vorrei provare a spiegare perchè nel nostro immaginario collettivo associamo a frequenze basse quote basse e a frequenze alte quote alte.
La mia opinione è legata alla direttività dei suoni in relazione alla loro frequenza. Dato che una sorgente sonora diviene tanto più direttiva quanto più alta è la sua frequenza, siamo indotti – incosciamente – a ritenere più alto un suono che risulta più potente quando in asse con l’orecchio. Se si sposta verticalmente un suono grave, la variazione in ampiezza non sarà così evidente come nel caso un suono acuto (ricordiamoci la funzione delle pieghe del padiglione, del rapporto che intercorre tra lunghezza d’onda della frequenza in arrivo e la dimensione dell’ostacolo e delle modifiche/riflessioni che le prime creano sulle onde di pressione).
Tendiamo altresì ad associare ai suoni più gravi dimensioni acustiche (e quindi fisiche) più grandi.
Nel DSR una delle idee ad esso connesse è quello di creare una distribuzione verticale congruente dello spettro sonoro mentre un’altra è quella di una dispersione orizzontale controllata in modo tale da rendere la scena acustica il più possibile stabile entro certi limiti al variare della posizione orizzontale (e in parte verticale) dell’ascoltatore rispetto ai diffusori.
Nel NPS un altro scopo è quello di aggiungervi la distribuzione verticale congruente della dimensione acustica creando una variazione del peso sonoro al variare della frequenza.
Il perchè di certe scelte va ricercato in alcune intuizioni e un enorme lavoro di ricerca sperimentale sul campo durato anni (le Audiolab Delta 4 erano datate 1977 se non erro ed erano già un tentativo inconscio ma comunque attuato di distribuzione verticale della sorgente sonora).
Renato aveva scoperto sperimentalmente che esisteva una relazione tra la naturalezza del suono che voleva ottenere da un diffusore, la distanza tra due trasduttori successivi e la lunghezza d’onda alla quale coincideva la frequenza di taglio tra i due.
Di qui le formule che ha pubblicato anche sul sito.
Per aumentare l’interazione tra diffusore e ambiente in modo tale da aiutare l’illusione di una prospettiva completa di profondità, era richiesto un maggior controllo timbrico dato dal rapporto il più possibile controllato di suono diretto e suono riverberato.
Partendo da una base già consolidata come il DSR orizzontale (ESB 7/06 per intenderci), il passo successivo è stato quello di tentare a dare una vera dimensione fisica al suono che usciva dai diffusori. Ma non in maniera incoerente o pseudo-lineare, bensì in maniera discriminata e controllata.
Ascoltando con attenzione – diciamo – audiofila molta musica dal vivo, in specie in sale da concerto, ti accorgi che i suoni non vengono solo da davanti, dai lati o da dietro l’ascoltatore.
Se ci si sofferma con più attenzione, ci accorgiamo che – in effetti – noi siamo completamente circondati dal suono e che anche il pavimento e il soffitto sono una sorta di sorgenti sonore supplementari che aiutano a dare una prospettiva sonora completa alle sorgenti. E, anch’esse, in debite proporzioni con il suono diretto.
Se quindi ci peritiamo di sfruttare il soffitto come secondo pavimento (ma questa volta sopra la nostra testa…), si può sfruttarne il rinforzo alle basse frequenze, per esempio.
Ma anche le sue riflessioni. E i modi ambientali pure; il compito del woofer a metà strada tra pavimento e soffitto serve anche a questo.
Non mi soffermo oltre, perchè Renato ha già spiegato il concetto (come già detto e comunque molto meglio di me).
Vorrei quindi provare a fornire, nella prossima sezione, un primo processo iterativo per iniziare a progettare un piccolo sistema a due/tre vie che faccia riferimento al concetto NPS.
Desidero ora, prima di chiudere questa prima parte introduttiva, citare quanto scritto da Renato Giussani sul suo sito riguardo la profondità della “scena acustica virtuale” e pregare l’attento lettore di soffermarsi all’esempio riportato cercando prima di immaginarlo e poi, appena possibile, di provarlo praticamente:
“…Ora andiamo un poco oltre.
Le sorgenti virtuali che vengono sottoposte alla correzione prospettica sono solo quelle il cui spettro contiene frequenze medie ed alte interessate alla variazione della dispersione del sistema DSR. La correzione poi sarà più o meno consistente a seconda di quanto è importante questa porzione dello spettro delle sorgenti considerate rispetto al loro spettro complessivo. Durante una registrazione dal vivo, le sorgenti più lontane avranno uno spettro sicuramente più povero in frequenze medie e alte rispetto alle sorgenti più vicine, che con il DSR vedranno la loro posizione virtuale corretta maggiormente.
Se provate ora a disegnare una tipica situazione d’ascolto come quella descritta e ponete dietro alla parete frontale due sorgenti virtuali centrali uguali (due violini?), l’una più vicina (magari proprio a 3 metri davanti a voi) e l’altra più lontana (facciamo dieci), dal centro le sentirete più o meno sovrapposte di fronte a voi, ma sarà difficile valutarne la distanza, dato che le uniche differenze fra i due segnali saranno costituite solo da diversi livelli e diverso spettro (che potrebbero anche essere emessi da due violini diversi suonati in modo diverso, ma magari l’uno accanto all’altro).
Ora spostatevi leggermente di lato. La sorgente più vicina, grazie al DSR, rimarrà fissa al centro fra le due casse, mentre quella lontana si sposterà lungo il segmento che congiunge le due casse, dalla stessa parte verso la quale vi siete spostati voi. Se congiungete, sul disegnino di prima, la vostra posizione con quella delle due sorgenti, vedrete che la retta che vi “unisce” alla sorgente lontata interseca appunto il segmento congiungente le due casse, non più al centro, ma dalla vostra parte.
Questo equivale a dire al cervello che quella sorgente virtuale, caratterizzata da uno spettro più “chiuso”, un livello più basso e che si è spostata seguendovi nel vostro movimento, evidentemente è “più lontana”.
Ora, se quanto descritto si verifica per lo spettro di tutti i segnali di una grande orchestra, ecco perché con un sistema DSR leggermente “sottocompensato in funzione della frequenza”, qual’è l’NPS delle 1000, la profondità della scena acustica aumenta… E questo anche con segnali monofonici….”
[segue nella seconda sezione: 2. Un esempio pratico ]
(24.06.2004: apportate alcune correzioni e aggiunte su suggerimento di Renato Giussani. Grazie per il contributo sul contributo!)
[last reviewed: 19/10/2004 20.07]
2. Un esempio pratico
Considerando i limiti tecnici del sistema che ci si può porre per non arrivare sino alle NPS-1000, si può rinunciare prima di tutto all’altezza massima disponibile (quella, intendo, soffitto/pavimento).
Si decide però di mantenere il woofer posizionato a metà strada, diciamo a 140 / 150 cm.
Dato che bisognerà creare un peso sonoro alla gamma bassa diverso e a favore della zona verticale inferiore, si deciderà di utilizzare due woofer per la parte basse della colonna e uno (come detto sopra a 140 / 150 cm da terra) per la parte alta.
Tra l’altro, il woofer più in basso sarà posizionato il più possibile in basso in modo da sfruttare il rinforzo naturale della sorgente speculare creata dal pavimento.
Un altro parametro importante sarà quello relativo all’altezza da terra del tweeter (o il gruppo midrange/tweeter).
Tale altezza sarà quanto più possibile uguale alla posizione d’ascolto media; diciamo tra i 100 e i 120 cm da terra in modo che il nostro orecchio sia in asse o leggermente sotto l’asse del tweeter (o del midrange, nel caso del gruppo mid/tweeter).
Decidiamo, per ora, di utilizzare tre mid-woofer da 130 mm e un tweeter da 19 mm per un sistema a due vie e vediamo se una tale scelta è attuabile in ambito NPS.
Proviamo a calcolare la distribuzione degli spettri e ad annotare le probabili quote degli altoparlanti.
Considerando il fatto che un mid-woofer da 130 mm in cassa difficilmente scenderà sotto gli 80 / 90 Hz e un tweeter da 19 mm sotto i 1500 Hz, si può calcolare quello che segue:
Range previsti per le 2 vie
A: 80 Hz –> 1500 Hz
B: 1 x Tweeter 19 mm.
B: 1500 Hz –> 20000 Hz
Tagli cross-over
![]()
![]()
![]()
(Distanza teorica DSR tra il centro acustico dei tre mid-woofer e il tweeter)
Centri Banda
![]()
![]()
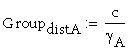
(Distanza NPS tra il centro acustico della coppia bassa dei mid-woofer e il terzo mid-woofer più in alto)
![]()
Questa è la distanza tra il centro acustico dei due mid-woofer in basso e quello in alto ed è plausibile; il problema che potremmo avere è che, deciso di mettere il mid-woofer alto a metà strada tra pavemento e soffitto (140 cm), i due mid-woofer bassi risulterebbero a un po’ meno di un metro da terra e quindi non si sfrutterebbe il rinforzo dato dalla sorgente speculare del pavimento. Potremmo però abbinare al sistema un sub-woofer per coprire la banda sotto gli 80 Hz.
Proviamo allora a fare un ragionamento inverso: quale sarà la larghezza di banda assegnata ai mid-woofer per far sì che la distanza di gruppo raggiunga un valore tale da mantenere il mid-woofer alto a 140 cm e i due bassi il più vicino al pavimento?
![]()
(I 17 centimetri sono da considerarsi il centro acustico da terra dei due mid-woofer bassi)
![]()
![]()
![]()
Come si può vedere, per un due vie è un po’ difficile mettere insieme le cose…
Proviamo con un tre vie, aggiungendoci un midrange in modo da alzare anche la frequenza di taglio bassa del tweeter e diminuirne le distorsioni? Vediamo.
Range previsti per le 2 vie
A: 3 x MidWoof 13 cm.
B: 1 x MidCono 10 cm.
C: 1 x Tweeter 19 mm.
A: 80 Hz –> 480 Hz
B: 480 Hz –> 2400 HHz
B: 2400 Hz –> 20000 Hz
Tagli cross-over
![]()
![]()
(Distanza teorica DSR tra il centro acustico dei tre mid-woofer e il midrange)
![]()
![]()
![]()
(Distanza teorica DSR tra il centro acustico del midrange e del tweeter)
![]()
Centri Banda
![]()
![]()
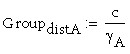
![]()
(Distanza NPS tra il centro acustico della coppia bassa dei mid-woofer e il terzo mid-woofer più in alto)
Quote dei centri di emissione degli altoparlanti (partendo dal basso)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Dato che il gruppo inferiore è composto da due altoparlanti mentre quello superiore da uno solo, il contributo acustico del gruppo più in basso sarà necessariamente superiore a quello più in alto. Il centro acustico reale dei tre mid-woofer sarà dunque più in basso rispetto al centro geometrico rappresentato dalla distanza NPS tra il centro acustico della coppia bassa dei mid-woofer e il terzo mid-woofer più in alto.
Quindi:
![]()
![]()
![]()
![]()
“Nell’NPS, l’espansione verticale della scena acustica, è ottenuta facendo riprodurre le varie porzioni nelle quali viene suddiviso lo spettro audio dalle diverse vie del sistema di altoparlanti, da zone emittenti aventi una dimensione verticale che approssimi al meglio la lunghezza d’onda della frequenza di centro-banda della porzione di spettro che riproduce. I centri delle varie zone di emissione delle porzioni dello spettro acustico riprodotto (costituite, fisicamente da altrettante vie ed altrettanti altoparlanti singoli e/o gruppi di altoparlanti) sono qui poste ad una distanza verticale fra loro molto piccola, in una sequenza che veda comunque aumentare la frequenza degli spettri riprodotti con l’aumentare della quota dal pavimento.”
[cfr.: Emissione NPS]
Da qui in poi possiamo ora sistemare le quote da terra del midrange e del tweeter.
Per fare ciò, potremmo supporre di applicare la distanza DSR tra il centro acustico reale del gruppo dei tre mid-woofer con il midrange ottenuta più sopra e poi la distanza DSR tra midrange e tweeter:
![]()
![]()
![]()
![]()
Ma dal brano riportato dal sito risulta che nella teoria NPS la distanza verticale dei centri di gruppi non omogenei sono sì a scalare in direzione verticale, ma a distanze che non seguono più la teoria DSR.
Resta dunque da decidere cosa mettere in asse (medio) con l’orecchio; il midrange, il tweeter oppure la media geometrica tra i due (ricordo che si è deciso di considerare l’asse tra 100 e 120 cm da terra).
Prendiamo la terza ipotesi:
![]()
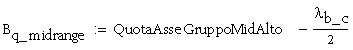
![]()
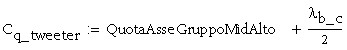
![]()
Alla fine, le quote dei cinque altoparlanti saranno (dall’alto in basso):
![]()
![]()
![]()
![]()
![]()
3. Conclusioni
Poche, per ora. Questo è solo un piccolo studio.
In effetti questa è solo una delle varie iterazioni che si possono eseguire. Per fare un semplice esempio, la distanza fra il centro acustico reale del gruppo dei tre mid-woofer con il midrange non è così piccola come forse dovrebbe (probabilmente con un quattro vie, queste distanze relative potrebbero essere un po’ più coerenti con la teoria NPS).
Non si è poi tenuto conto della possibile risposta polare verticale del sistema.
In fondo, conviene affiancare l’uso di CrossPC per verificare e correggere e/o riformulare le ipotesi di progetto; ricordo il programma è scaricabile e utilizzabile gratuitamente dal sito di Renato Giussani seguendo il link:
Cross-PC e Bass-PC Dos con Windows
Insomma, questo modestissimo scritto vuole essere solo un invito alla lettura e alla sperimentazione di idee originali e concrete intorno al sistema NPS.
[ …andrea riderelli… ]
[last reviewed: 19/10/2004 20.52]
Leave a Reply